 |
|
МЕНЮФестивали и конкурсы Семинары Издания О МОДНТ Приглашения Поздравляем НАУЧНЫЕ РАБОТЫ |
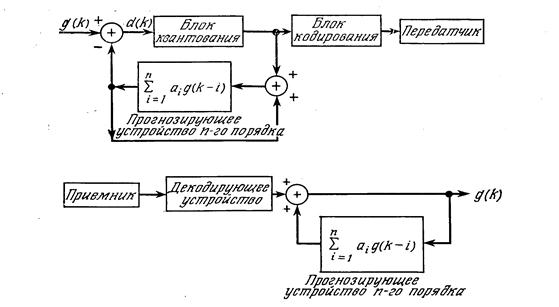
Реферат: Дискретизация и квантование изображений4.3.2. Схемы сокращения избыточности изображений с обработкой в пространственной области В одном из возможных вариантов схемы сокращения избыточности видеоинформации в первом блоке (схема рис. 4.7) выполняется операция тождественности, т.е. исходная картинка никак не изменяется, а все сжатие достигается за счет квантования и кодирования. Однако сжатие информации невозможно выполнять без использования критериев, учитывающих особенности наблюдателя и свойства передаваемых данных. Если, например, наблюдателю нужна точность 1/1000 , то необходимое число уровней квантования получается при использовании 10-разрядных двоичных чисел; если же допустима точность 1/8 , то достаточно взять 3-разрядные числа. Следовательно, квантование при сжатии информации играет ограниченную роль. Однако сокращения избыточности можно добиться при кодировании, и одной из основных задач после создания Шенноном теории информации было построение кодов, оптимальных с точки зрения сокращения избыточности информации. Шеннон доказал, что существует код, для которого скорость передачи совпадает со скоростью создания информации источником. Таким образом, для изображений с энтропией порядка 1 бит/точка существуют схемы кодирования, позволяющие построить коды со средней длиной в 1 бит/точка. К сожалению, само по себе существование таких кодов бесполезно, если отсутствуют алгоритмы их построения. Известны алгоритмы построения кодов, приближающихся к оптимальным. Например, кодирование по Хаффмену является эффективной процедурой для согласования кода со статистикой источника информации и позволяет сократить длину сигнала по сравнению со стандартной ИКМ. Однако подобные коды имеют переменное число сим1волов (т.е. при передаче сообщений кодовые слова состоят из различного числа символов); при кодировании и декодировании требуются сложные алгоритмы, связанные с записью, синхронизацией и вспомогательным накоплениям информации. Кроме того, вид подобных кодов очень сильно зависит от вероятности создания символов источником, и любые изменения вероятности могут привести к ухудшению характеристик кода (очень значительному в некоторых случаях). Следовательно, кодирование с квантованием может служить основным средством сжатия видеоинформации лишь в ограниченном числе случаев, так что необходимо искать другие методы. В качестве метода сжатия видеоинформации в плоскости пространственных координат, выполняемого )в первом блоке схемы рис. 4.7, наиболее широко применяется дифференциальная импульсно-кодовая модуляция (ДИКМ). По своей структуре схемы ДИКМ совпадают со схемами кодирования методом линейного предсказания (КЛП), применяемым при сжатии полосы речевых сигналов, и поэтому схемы ДИКМ изображений иногда называют схемами сжатия методом предсказания. Блок-схема ДИКМ приведена на рис. 4.8. В этом методе используется статистическая взаимосвязь яркостей отдельных точек изображения и для каждой точки формируется оценка яркости в виде линейной комбинации яркостей предшествующих точек. Под предшествующими точками подразумеваются точки, расположенные перед рассматриваемой точкой при развертке изображения сверху вниз и слева направо (как в телевидении), благодаря чему создается вполне определенный порядок следования точек изображения. Подобная схема, конечно, будет применима и тогда, когда изображение уже «развернуто» методом сканирования. Затем вычисляется и квантуется разность между фактическим значением яркости и ее оценкой. Квантованная разность подвергается кодированию и передается по каналу. На приемном конце символы декодируются, а информация восстанавливается с помощью схемы линейного предсказания n-го порядка (конечно, идентичной соответствующей схеме на передатчике), в которой формируются оценки яркости, добавляемые к разностям, полученным по каналу. Схемы предсказания, изображенные на рис. 4.8, называются схемами с предсказанием назад , поскольку квантование сигнала
Рис. 4.8. Блок-схема системы сжатия методом ДИКМ с предсказывающим устройством n-го порядка. происходит внутри петли обратной связи, а при восстановлении сигнала предсказанное значение подается по схеме назад. Можно спроектировать схемы ДИКМ, в которых предсказанные значения сигнала подаются вперед, а также создать схемы ДИКМ, где блок квантования расположен вне петли обратной связи. Однако такие системы дают восстановленное изображение с большими ошибками. Схема с предсказанием назад необходима в приемнике потому, что символы поступают последовательно. При использовании в передатчике аналогичной схемы предсказания назад в случае отсутствия ошибок, связанных с квантованием, можно было бы восстановить изображение с абсолютной точностью. Если схему квантования включить в петлю предсказывающей схемы передатчика, то и в приемнике, и в передатчике предсказание будет осуществляться на основе одинаковых квантованных отсчетов, что позволит уменьшить ошибки восстановления. Сжатие в схемах ДИКМ достигается за счет вычитания сигналов, поскольку разности имеют значительно меньший динамический диапазон. Предположим, например, что исходное изображение передается методом ИКМ и для представления яркостей его точек нужны числа от 0 до 255. Тогда, если допустимая ошибка равна единице младшего разряда, то необходимо квантование в 8-разрядные числа. Однако значения разностей яркостей соседних точек будут гораздо меньшими; если разности (в том же масштабе) будут изменяться от 0 до 7, то для получения ошибки, равной единице младшего разряда, достаточно квантования в 3-разрядные числа. Поскольку идея ДИКМ достаточно проста, то, как следует из схем рис. 4.8, характеристики системы сокращения избыточности изображений методом ДИКМ определяются [порядком предсказывающего устройства п, значениями коэффициентов прогнозирования аi, числом уровней квантования и их расположением. Порядок предсказывающего устройства зависит от статистических характеристик изображения. Как правило, если последовательность отсчетов может быть промоделирована авторегрессионным марковским процессом п-го порядка, то разности, полученные с помощью оптимального предсказывающего устройства п-го порядка, будут образовывать последовательность некоррелированных чисел [20]. Изображения, очевидно, не являются марковскими процессами п-го порядка, но опыт работы по сжатию изображений показывает, что корреляционные свойства изображений можно описать марковским процессом третьего порядка, а это приводит к предсказывающим устройствам третьего порядка (п=3) [22]. Аналогично при моделировании изображений было выяснено, что ДИКМ с предсказывающими устройствами более высоких порядков не дает большего выигрыша в качестве изображения (как по субъективным, так и по объективным данным). Коэффициенты предсказания аi можно
определить с помощыо анализа средних квадратических ошибок. Пусть g(k)
- отсчеты на строке развертки, a min e = E { g(k) - по всем k, аi Это известная задача, и если процесс g(k) стационарен, то ее решение имеет вид [25] где r ( j - i ) = E [ g ( k - j ) g (k -i ) ] (4.23) обычно называется автокорреляционной функцией процесса g. Коэффициенты ai получаются решением системы уравнений (4.22). Оптимальные значения коэффициентов предсказания зависят от взаимосвязей точек изображения, описываемых автокорреляционной функцией. Из определения (4.20) видно, что в случае стационарных данных автокорреляционная функция отличается от вышерассмотренной функции на постоянную величину. При нестационарных данных функция r (в уравнении (4.23) зависит от пространственных переменных и оптимальные коэффициенты предсказания должны изменяться в зависимости от пространственных координат. Это характерно для изображений. К счастью, нестационарные статистические характеристики изображений обычно можно достаточно хорошо аппроксимировать стационарными функциями, так что неперестраивающееся линейное устройство предсказания дает вполне хорошие результаты. При сжатии видеоинформации методом ДИКМ ошибки обычно появляются на границах изображаемых предметов, где предположение о стационарности удовлетворяется в наименьшей степени, и на восстановленном изображении воспринимаются визуально как аномально - светлые или темные точки. Выбор числа уровней квантования и расположения порогов квантования является задачей отчасти количественной и отчасти качественной. Расположение порогов квантования можно найти количественными расчетами. В работе Макса [26] впервые было рассмотрено неравномерное квантование, зависящее от функции распределения квантуемого сигнала и сводящее к минимуму среднее квадратическое значение ошибки, вызванной ограниченностью числа уровней квантования. Алгоритм Макса позволяет найти оптимальное расположение точек перехода для заданного числа уровней квантования. Однако число уровней квантования выбирается исходя из субъективных качественных соображений. Минимальное число уровней квантования paвно двум (одноразрядные числа) и соответствует такому квантованию изображений, при котором разность яркостей принимает фиксированное (положительное или отрицательное) значение. Этот способ обычно называют дельта - модуляцией, схему ДИКМ (рис. 4.8) можно упростить заменой квантователя на ограничитель, а предсказывающего устройства n-го порядка на интегратор. При сокращении избыточности изображений методом дельта-модуляции наблюдаются те же недостатки, что и при дельта-модуляции других сигналов, например речевых [27], а именно затягивание фронтов и искажения дробления. Однако если частота дискретизации изображения выбрана намного больше частоты Найквиста, то сжатие методом дельта - модуляции приводит к малым (субъективно замечаемым) ошибкам. Если частота дискретизации приближается к частоте Найквиста, то на изображении в большей степени будут проявляться затягивания фронтов (на контурах изображений) и искажения дробления (на участках с постоянной яркостью). Как и при сжатии речи [27], адаптивная дельта-модуляция позволяет уменьшить эти ошибки. Однако в целом при передаче изображений дельта - модуляция оказалась менее эффективной, что при передаче речи. Квантование с числом уровней, большим двух, позволяет при сокращении избыточности получить изображения более высокого качества. Система сжатия методом ДИКМ с 8-уровневым (З-разрядным) квантованием при оптимальном размещении порогов дает изображения, качество которых такое же, как в системе с ИКМ, имеющей разрядность от 6 до 8. Исключение составляют ошибки вблизи линий резкого изменения яркости. Сигнал с выхода устройства квантования, конечно, следует кодировать, поскольку распределение вероятностей «квантованных разностей не является равномерным. При удачном выборе кода (например, кода Шеннона — Фано или Хаффмена) удается дополнительно понизить общую скорость создания информации. Прэтт [28] указывает, что при использовании кода Хаффмена в пределе удается понизить скорость создания информации до 2,5 бит/точка. Это дополнительное понижение скорости требуется сопоставить с увеличением стоимости и сложности запоминающего устройства, синхронизаторов и вспомогательных регистров памяти, необходимых для работы с кодами Хаффмена. Выше обсуждались вопросы сжатия изображений с помощью ДИКМ при выборе элементов по строке (т.е. для прогноза брались точки, лежащие на текущей строке развертки). В силу двумерного характера изображений возможно (и целесообразно) расширить метод ДИКМ так, чтобы при прогнозе учитывались яркости в точках, лежащих не только на текущей, но и на предшествующих строках развертки. Схемы сжатия методом ДИКМ с таким двумерным предсказанием основаны на тех же принципах, что при одномерном предсказании. Поскольку для изображений характерно наличие двумерных статистических взаимосвязей, можно надеяться, что двумерное предсказание даст лучшие результаты по сжатию изображений, так как декорреляция изображений с помощью операций предсказания и вычитания будет производиться по двум координатам. Действительно, устройства с пространственным предсказанием дают более качественные изображения. Хабиби [22] показал, что с помощью двумерного предсказывающего устройства третьего порядка при 8 - уровневом (3 - разрядном) квантовании получались изображения, которые визуально не удавалось отличить от исходных фотографий, обработанных методом ИКМ с 11- разрядными числами. Для изображений, состоящих из последовательных кадров, например телевизионных, идеи предсказания и вычитания, связанные с ДИКМ, можно распространить на временную область. В подобных изображениях яркость многих точек от кадра к кадру не изменяется или изменяется медленно. Следовательно, можно построить систему сжатия методом ДИКМ, в которой яркость очередной точки прогнозируется на основе яркостей двумерного набора точек текущего кадра и соответствующих точек предшествующих кадров. На практике порядок временного предсказания не может быть высоким, так как для каждого временного слагаемого необходимо иметь запоминающее устройство, где сохранялся бы весь кадр. Моделирование с предсказывающим устройством третьего порядка, в котором для предсказания использовались точки, расположенные в данном (и предшествующем кадрах слева от рассматриваемой точки и вверх от нее, показало, что можно получить очень хорошие изображения при средней разрядности 1 бит/точка [28]. 4.3.3. Схемы сокращения избыточности изображений с обработкой в области преобразований Для пояснения основных операций, выполняемых системой сжатия видеоинформации с обработкой в области преобразований, обратимся к ковариационной матрице, определяемой соотношением (4.20). Матрица [Cg] описывает корреляцию отсчетов изображения в плоскости (х, у), являющейся координатной плоскостью изображения. Важным методом многомерного статистического анализа служит исследование массива данных не только в их естественных координатах, но и в системах координат с более удобными свойствами. В частности, весьма полезными оказались системы координат, основанные на собственных значениях и собственных векторах ковариационной матрицы [ Cg ] = [ Ф ] [ где
[Ф] - матрица, составленная из ортогональных собственных вектор -
столбцов Фi а [ Преобразование координат, определяемое матрицей собственных векторов [Ф], обладает тем свойством, что оно производит преобразование заданного массива чисел в другой с некоррелированными элементами, причем получающиеся компоненты имеют убывающие дисперсии. Пусть собственные значения матрицы [Cg] расставлены в убывающем порядке и пронумерованы так, что и пусть собственные векторы, связанные с ними, расставлены в том же порядке. Тогда матрица собственных векторов [Ф] обладает тем свойством, что умножение ее на вектор-изображение g (образованный лексикографической расстановкой) дает вектор G = [ Ф ]g , (4.26) имеющий некоррелированные компоненты, причем компоненты вектора G оказываются расставленными в порядке убывания их дисперсий [29], что является свойством дискретного варианта разложения Карунена - Лоэва, фактически описанного соотношениями (4.24) - (4.26). Полезность преобразования Карунена — Лоэва ( КЛ, или ковариационного) для сокращения избыточности изображений очевидна. Массив отсчетов изображения заменяется набором переменных, имеющих различные статистические веса ). Сжатие можно получить, отбрасывая переменные с малым статистическим весом и сохраняя остальные. Если, например, оставить M<N2 компонент вектора G и передать их вместе со специальной информацией о том, какие компоненты сохранены, то можно сузить ширину полосы в N2/M раз. В приемнике из принятых М чисел образуют N2 - компонентный вектор путем подстановки нулей вместо N2-М непереданных компонент. Из этого нового вектора, обозначенного как G' , с помощью преобразования gc = [ Ф ]TG’ (4.27) восстанавливается исходное изображение. В процессе сжатия возникает средняя квадратическая ошибка || g - gc || = особенность КЛ - преобразования состоит в том, что из всех линейных преобразований именно оно обеспечивает минимальную величину этой ошибки. Из соотношений (4.25) и (4.26) видно, что число операций,
необходимых для выполнения КЛ - преобразования, пропорционально N4, так как исходный массив содержит N2 отсчетов. Для
типичных значений N ( N = 256 или 512 ) такое число чрезмерно велико. Еще труднее
вычислить собственные значения и собственные векторы ковариационной матрицы [Cg] размером N2 [Cgp] = где Q=N/P, a gi - вектор, построенный из отсчетов i-го блока. Тогда, если [Фp] - матрица собственных векторов, связанных с P2 собственными значениями, расположенными так же, как в формуле (4.25), то операции по сокращению избыточности для каждого из блоков выполняются по формулам (4.26) и (4.27),. как для полного изображения, но матрица [Ф] заменяется на [Фp]. Как правило, радиус корреляции большинства изображений имеет такую величину, что Р=16 является разумным компромиссом между размером ковариационной матрицы и скоростью, с которой коэффициент корреляции отсчетов приближается к нулю [30]. Длительность вычислений, выполняемых при сжатии видеоинформации поблочно, пропорциональна Q2/P4. Страницы: 1, 2, 3, 4, 5, 6, 7, 8 |
Приглашения09.12.2013 - 16.12.2013 Международный конкурс хореографического искусства в рамках Международного фестиваля искусств «РОЖДЕСТВЕНСКАЯ АНДОРРА»09.12.2013 - 16.12.2013 Международный конкурс хорового искусства в АНДОРРЕ «РОЖДЕСТВЕНСКАЯ АНДОРРА»
|
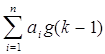 }
(4.21)
}
(4.21)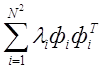 ,
(4.24)
,
(4.24)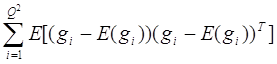 ,
(4.29)
,
(4.29)

Copyright © 2012 г.
При использовании материалов - ссылка на сайт обязательна.